How To: Extract HTML Page Titles with Inspyder Power Search
A Quick guide to capturing all the page titles on a website.
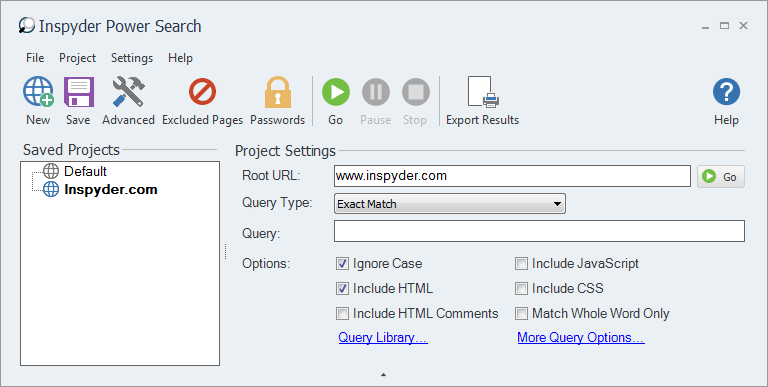
Step 1: Enter your Root URL
Run Power Search and enter the URL of the website you want to work on. For this example, we’ll use ‘www.inspyder.com‘.
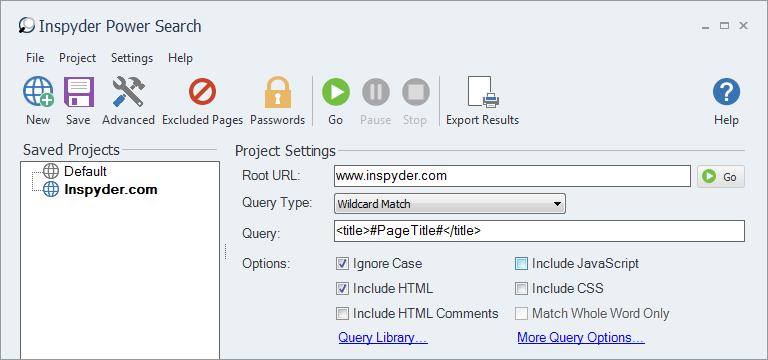
Step 2: Enter your Query
Enter the following into the Query field (no quotes): “#PageTitle#“. Set the Query mode as “Wildcard“.
This query will extract any text found on each webpage between thetags and store it into a field in the results called “PageTitle“. Later, we can export the results and open them in Excel for further analysis.
Step 3: Configure Additional Settings
Ensure that “Ignore Case” and “Include HTML” Query Options are checked. Ignore case tells Power Search to match thetags in upper or lower case. Include HTML tells Power Search not to remove the HTML tags before using our query on the page.
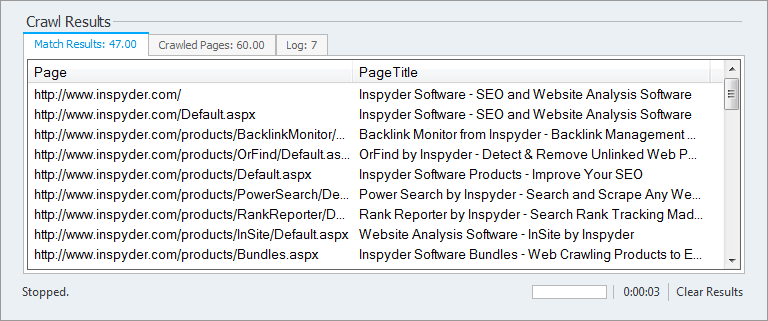
Step 4: Click Go!
Click the “Go” button to start the crawl. Power Search will go through each page on the site and capture all the text found between HTMLtags. You can stop the crawl at any time by clicking the red “Stop” button. When the crawl is completed you can export the results by clicking “Project > Export Results…” from the main menu.
Minimum Requirements
- Windows XP SP2 or Higher
- 32-bit and 64-bit supported
- 1GB RAM
- 1GB of available hard disk space
